Claude 3 launched by Anthropic — new AI model leaves OpenAI's GPT-4 in the dust

Claude 3 is the latest large language model from AI lab Anthropic and it promises to give both OpenAI's GPT-4 and Google's Gemini a run for their money.
The latest generation of the popular chatbot and AI model comes in three versions, Opus, Sonnet and Haiku, each serving different markets and purposes.
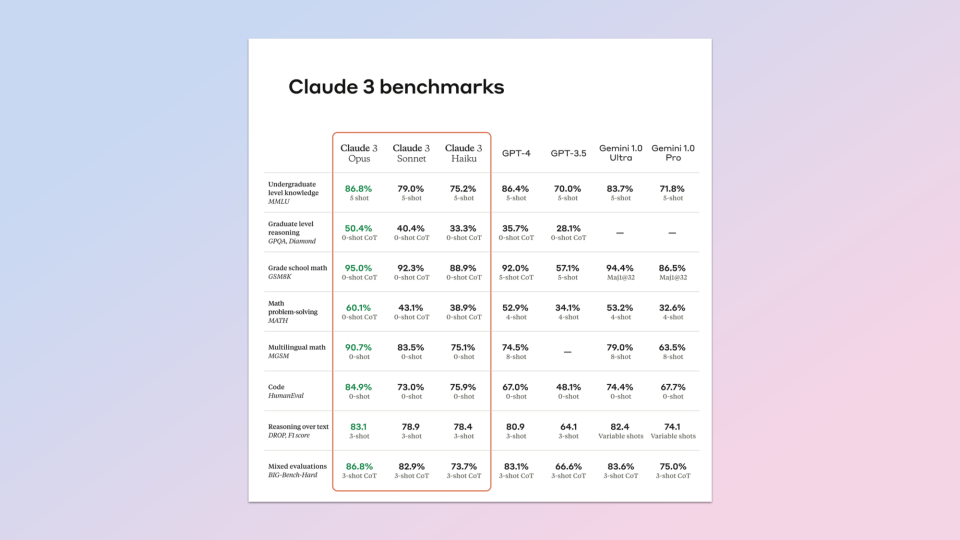
During benchmarking Anthropic said Claude 3 Opus, the largest of the models, beat GPT-4 and Gemini 1.0 Ultra on undergraduate level knowledge, graduate level reasoning by a significant margin and on grade school math.
Opus powers the paid-for version of the Claude chatbot, Sonnet the free version and Haiku is a cheaper to run model available for third-party developers. Sonnet is also available on AWS Bedrock for companies and developers to use in applications.
What is Claude?
Claude was one of the early AI chatbots, launching soon after OpenAI's ChatGPT and providing a similar experience. The main focus for Anthropic has been on the enterprise market but Claude has always been a useful alternative.
As well as a chatbot Claude 3 is available as an API for third-party developers to create their own applications. The Opus and Sonnet models are available at launch in 159 countries with Haiku coming soon.
I've used Claude since the first version and have always found it more creative than either ChatGPT or Gemini. It does have a hallucination and refusal problem but Anthropic says it has solved that with version 3.
This is the first time Claude has had the ability to view more than just text and code. It is now a vision model able to see photos, charts, graphics and technical diagrams.
It beat Claude 3 on math and reasoning when analyzing images. Interestingly the mid-tier Sonnet model beat out Opus, GPT-4V and Gemini Ultra on understanding science diagrams.
What's new in Claude 3?
Testing an AI model is never easy and there are nuances in evalations and generation that don't always compare but in almost all common benchmarks Claude 3 has comfortably beat both GPT-4 and Gemini Ultra.
The most popular model, Opus, "exhibits near-human levels of comprehension and fluency on complex tasks, leading the frontier of general intelligence," the company declared, hinting that we're closing in on artificial general intelligence.
What should be noted is that this is a comparison to OpenAI's year old model and we're expecting GPT-5 to drop at some point this year.
"We do not believe that model intelligence is anywhere near its limits, and we plan to release frequent updates to the Claude 3 model family over the next few months," Anthropic said in a statement.
What about the context window?
While Google gained a lot of attention for the potential 10 million token context window — the memory of a single chat — for Gemini Pro 1.5, Claude was the first to pass the 100,000 token barrier.
The new models will have a 200,000 token context window on launch but Anthropic is testing up to one million tokens in house and with testers.
However, having a large context is only meaningful if it also comes with the ability to recall information from any point within that window. This is something Google managed to tackle with Gemini Pro 1.5.
Anthropic says on the 'Needle In A Haystack' (NIAH) evaluation, also used by Google, Claude 3 Opus achieved near-perfect recall with 99% accuracy and identified limitations within the evolution process by spotting the "needle" sentence itself.
What about AI safety?
Since its launch Anthropic has focused carefully on AI safety. This includes tracking the safety level of its models, highlighting potential risks and creating a novel "constitution" for AI to follow that keeps it aligned to human values.
"As we push the boundaries of AI capabilities, we’re equally committed to ensuring that our safety guardrails keep apace with these leaps in performance," a spokesperson for Anthropic said.
"Our hypothesis is that being at the frontier of AI development is the most effective way to steer its trajectory towards positive societal outcomes."
