How FamilySearch is using the future to discover the past with AI

FamilySearch has made more than 2.6 billion historical resources available to the public, and according to John Alexander who is a senior product manager there, there’s a lot more on the way. It’s just a matter of getting the documents transcribed.
More than 5 billion more documents — collected and converted to digital images — need to be transcribed to make them searchable and usable in FamilySearch’s database.
And 1 to 2 million more are added every single day.
With the development of new artificial intelligence technology, there’s more hope of getting billions of records to families looking for information about their relatives in as little as five years. And it’s already being tested and used.

“In just a couple of hours, the computer can index more than you or I could do in a whole lifetime if we did nothing besides indexing for the rest of our lives,” Alexander said. “So in terms of efficiency, it’s very fast.
“In just a couple of hours, the computer can index more than you or I could do in a whole lifetime if we did nothing besides indexing for the rest of our lives,” Alexander said.
Currently, it’s being taught — yes, “taught” like a child — English, Spanish and Portuguese, with plans for Italian in 2023.
Teaching AI to read hand-writing
It takes time to get a sophisticated system like transcribing AI up and running because it has to be taught and trained, Alexander said.
“When we show a computer the image, all it sees is ones and zeros — pixels,” he explained. “None of that means anything to the computer.”
“And so we have to train it similar to the way we train or teach a child to read, we have to teach it each individual letter and character, we have to teach it the way that pages are laid out how each line is distinct from the other,” he continued. “All of that takes time and training.”

Not to mention that it’s starting to read handwriting from the 1400s, which can be difficult for human volunteers.
Once it’s taught a language, the other languages in the family become much easier to teach — it’s a sort of exponential process.
And quicker than they could’ve imagined, the AI could read documents in English, Spanish and Portuguese, and index what would take human indexers half a century in just a few months.
Drowning in documents
Unless there’s a rapid uptake in indexing these documents, these records will never be accessible to the public, which is FamilySearch’s goal.
“Much of what family search does is gather and store the world’s historical records,” Alexander continued, “especially those records that tell about people and their relationships to each other.”
Since the 1940s, FamilySearch has sent cameras out to different parts of the world to capture and preserve historical documents, like old church books that contain births, baptisms, marriages and burials, or censuses that tell all about the people who live in the household with age and parents.
Last year, they finished digitalizing 60-plus years of gathered microfilm documents.
Related
“Here’s the problem that we’ve been having. In order for those images to be useful and accessible for people to find their families on them, they need to be indexed,” he said.
Alexander said only about 20% of the documents that FamilySearch has been able to collect and copy information from is readily available on the site — and they’re quickly losing footing as documents are copied and stored faster than the information can fly off the page.
Indexing, like Alexander referenced, is a man-powered process that is run by volunteers who can go through and look at the image, and fill out a digital form with the information from the historical document. This allows the information to be put in the online database and searchable to any user across the globe.
But it’s limited because humans can only work so fast.
“Even though we’ve tried to grow our family search indexing and get more people involved, digitization has gotten so much faster, we can’t keep up,” Alexander said. “We can’t index all of the images coming in the door.”
Related

Quality control
Whenever AI gets involved, some skepticism enters the equation. A common question about the whole transcribing AI process is, “How accurate is it?”
“The computer does make mistakes,” Alexander said. “It might read the name of a street and think that’s the name of the baby — things like that.”
But FamilySearch — he added — is very committed to quality records and plans to maintain that high quality for users on the site. Records that don’t meet a certain quality threshold are not published on the site.
“If we didn’t worry about quality, we could go much, much faster with the computer,” said Alexander. “But we care very much about the quality.”
FamilySearch has processed far more documents than it has released to the public because of quality thresholds that are in place, giving the document a grade based on its accuracy. And it’s all thanks to quality-control volunteers.
Human indexers aren’t out of a job
This is done through a volunteer program on the “Get Involved” page on the website launched at RootsTech 2022, which allows volunteers to look through the indexed information to check for accuracy.
It comes up with suggestions based on what the AI has read for the volunteer to accept, deny or skip the information like the picture shows below.
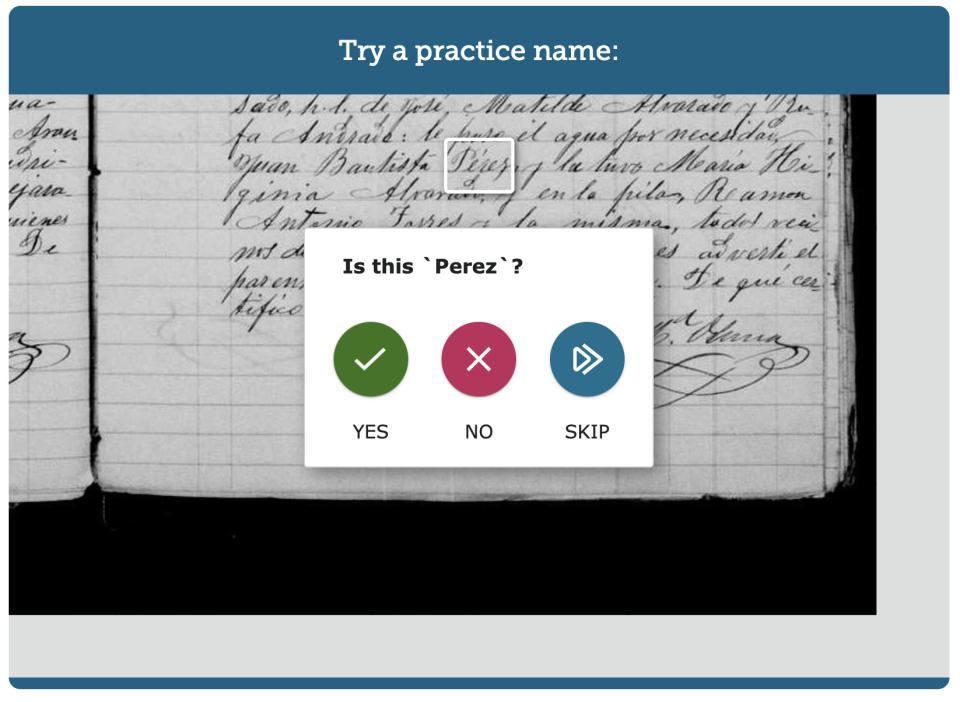
But until the AI process is perfected, volunteers are still needed to “make sure that the computer indexed correctly.”
“The computer automation isn’t going to replace our volunteer indexers,” Alexander said. “If anything, we need more of them.”
“The computer automation isn’t going to replace our volunteer indexers,” Alexander said. “If anything, we need more of them.”
Although the transcribing AI is still in its beginning stages, the FamilySearch team is very optimistic about what it means for family history work.
“The amount of information available for genealogists, researchers, people wanting to discover and find their families, and then the search systems behind them to help are going to be tremendous in the future,” Alexander said. “And we’re going to see really wonderful experiences coming from this technology, specifically in the family history space.”

Related
